最近,总会聊到慢SQL优化的问题,虽然我总坚持在合理边界划分的情况下,不应该出现复杂SQL,只要加上合适的索引,就不会出现慢查询的问题。但细了解下来,还是有许多值得总结学习的地方。
收集
性能优化这个事情,说白了应该在出现性能问题的地方进行优化,而不是纯粹拿一些原则方法来,就说这不行,那不好。所以,优化的第一步,就是我们需要去发现那些慢查询。
druid
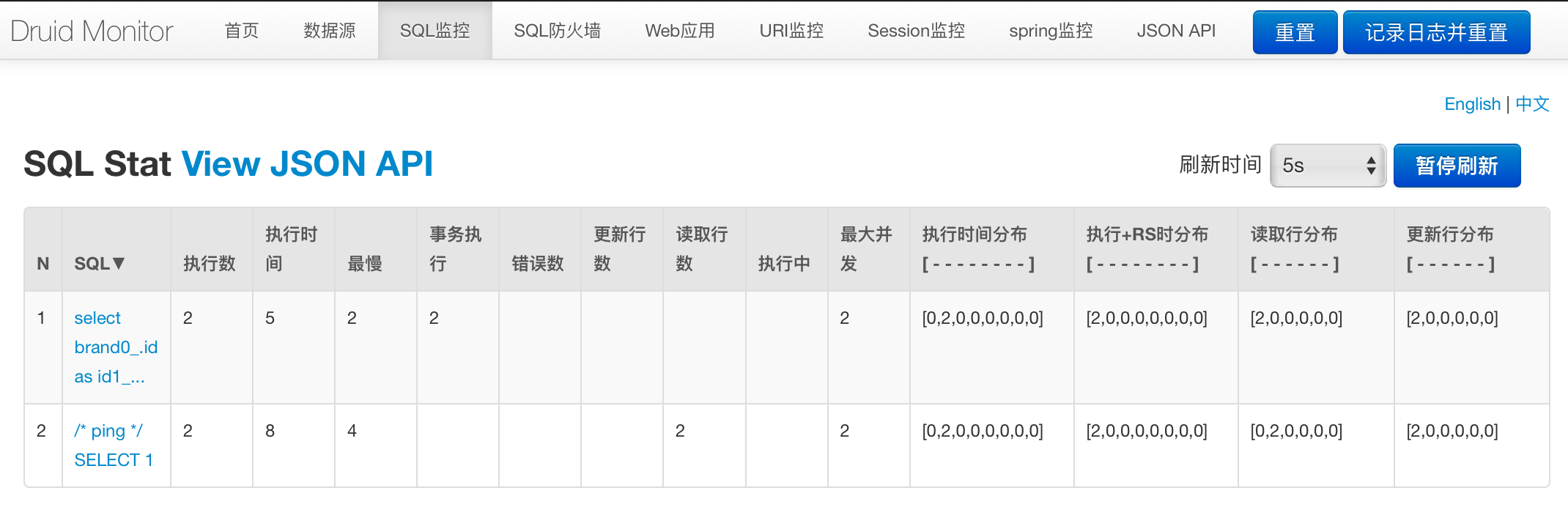
做Java开发的同学,应该都听过阿里druid的大名,它是最好的数据库连接池,并且提供了强大的监控和扩展功能。
通过监控,我们可以清楚地看到我们执行了哪些SQL,以及这些SQL执行的时间,执行的次数等等一系列信息,从这里我们就可以找到需要优化的SQL,有针对性得优化。
开启 MySQL 慢查询日志
另外一个,就是在 MySQL 上开启慢查询日志。
-- 日志文件位置
set global slow_query_log_file='/usr/local/mysql/sql_log/mysql-slow.log';
-- 把没有使用索引的SQL记录到日志中
set global log_queries_not_using_indexes=on;
-- 开启慢查询日志
set global slow_query_log=on;
并且修改 /etc/my.cnf 文件,设置超过多少秒的查询记录到慢查询日志中,比如这里设置为1秒。
long_query_time=1
之后执行的超过1秒的SQL就会记录在慢查询日志中,日志以下面的格式进行记录。
# Time: 2019-03-18T08:37:49.821914Z
# User@Host: root[root] @ localhost [] Id: 8
# Query_time: 0.000233 Lock_time: 0.000112 Rows_sent: 2 Rows_examined: 2
SET timestamp=1552898269;
select * from store limit 10;
这里记录着执行时间,主机信息,SQL执行信息,SQL执行时间及执行的SQL。
使用慢查询分析工具
记录到的慢查询日志,我们可以使用日志分析工具进行分析。
mysqldumpslow 是 MySQL 自带的分析工具,拿来即用,非常方便,可惜分析的结果比较简单,功能不够强大。
mysqldumpslow -t 3 /var/lib/mysql/cartisan04-slow.log
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hosts
# Time: N-N-18T08:N:N.821914Z
# User@Host: root[root] @ localhost [] Id: N
# Query_time: N.N Lock_time: N.N Rows_sent: N Rows_examined: N
SET timestamp=N;
select * from store limit N
另外,可以安装 percona 的 pt-query-digest。 PS:percona包中还含有其它一些强大好用的工具,比如查看定义的冗余索引 pt-duplicate-key-checker 及通过慢查询分析不使用的索引 pt-index-usage等。
# 安装源
sudo yum install http://www.percona.com/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
# 安装percona-toolkit包
sudo yum install percona-toolkit
分析慢查询日志。
pt-query-digest /var/lib/mysql/cartisan04-slow.log
它不仅有详细的分析结果,并且支持分析结果输出到文件或者数据库中,具体可以查看帮助文档。
如何发现有问题的SQL
- 查询次数多并每次查询时间长的SQL,通常为pt-query-digest分析的前几个查询
- IO大的SQL,注意pt-query-digest分析中的Rows examine项
- 未命中索引的SQL,注意pt-query-digest分析中Rows examine和Rows Send的对比
分析
通过 explain 分析 SQL 的执行计划
我们通过慢查询日志得到慢SQL后,可以通过 explain 进行分析这条SQL的查询计划。

- table:这一行的数据是关于哪张表的
- type:连接使用了何种类型
- possible_keys:可能应用在这张表中的索引
- key:实际使用的索引
- key_len:索引的长度
- ref:索引的哪一列被使用了
- rows:MYSQL认为必须检查的用来返回请求数据的行数
- extra:其它信息
慢查询的关注点
除了关注是否使用索引(key)与用来返回请求数据的行数(rows)外,主要关注 type 与 extra 两列。
type 连接使用何种类型,从最好到最差的连接类型如下: + const 常数查询,一般对于主键或唯一索引 + ref_eq 范围查找,结果集只会有一个,一般针对唯一索引的范围查找 + ref 使用了索引而且不为主键或唯一索引 + index 基本就是使用了索引的全表扫描 + ALL 全表扫描
extra 字段需要注意返回值,当 Using filesort 或 Using temporary 时,查询就需要优化了。
+ Using filesort:MySQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行。
+ Using temporary:MySQL需要创建一个临时表来存储结果。这通常发生在对不同的列集进行Order By上,而不是Group By的字段上。
SQL 语句优化
在 SQL 语句方面,单表的查询只要有合适的索引,一般问题都不大。主要出现在关联查询,子查询,特别是一些使用到 group by、order by 等操作时,要关注是否扫描行数过大,是否使用临时表,及索引的应用情况,这些要么引起大数据量的扫描,要么增加 IO 操作,都是影响效率的祸根。
count 和 max 优化
- max 当只获取一个max的结果时,给参与max字段的函数建立索引,这样就是覆盖索引,结果完全可以从索引中获取,不需要扫描表。
- count count(*)会计空值,count(id)不会计空值。
子查询的优化
通常情况下,需要把子查询优化为join查询,但在优化时要注意关联键是否有一对多的关系,要注意重复数据。
group by 的优化
如果出现多表关联,最好选用同一表中的列进行 group by,否则容易出现使用临时表,就会增加IO操作,影响效率。
limit 优化
limit 常用于分页处理,时常会伴随 order by 从句使用,因此大多时候会使用 filesorts,这样会造成大量 IO 的问题。
- 使用有索引的列或主键进行 order by 操作
- 记录上次返回的主键,在下次查询时使用主键过滤,避免出现数据量大时扫描过多的记录,缺点在于 id 必须是连续的,不断的。
索引优化
在合理的 SQL 下,索引是提升效率的关键。
如何选择合适的列建立索引
- 在 where 从句,group by 从句,order by 从句,on 从句中出现的列。
- 索引字段越小越好,因为索引存储是页为单位的,一页里存储的索引数据越多,效果越好。
- 离散度大的列放到联合索引的前面,唯一值越多,离散值越好。
当一个索引包括了查询中所有的列,这种索引为覆盖索引,效率最高,直接从索引返回数据。
索引的维护及优化
索引可以提高查询效率,但是会降低写入效率。而且,当出现重复及冗余索引时,查询时需要选择使用哪个索引,也会降低查询效率。
- 重复索引
相同顺序建立的同类型索引
- 冗余索引
多个索引的前缀列相同,歌者在联合索引中包含了主键的索引,InnoDB 的一个特性就是在所有的索引后面添加主键信息,所以人为加上主键,就变成了冗余索引。
- 清除不再使用的索引
不再使用的索引要及时清除,不过要注意一主多从的表,要把所有主从表放在一起分析,因为有些在一个从上不使用,在其它从上还有使用,或者在主上不使用,在从上还在使用。
表结构优化
选择合适的数据类型
- 使用可以存下你的数据的最小的数据类型。比如时间即可以用 varchar,也可以使用日期时间型,也可以使用时间戳,也可以使用 int,显然 int 最小,时间戳也是可以的,在 MySQL 里时间戳与 int 是一样大小的。使用 int 来存储,使用时可以用 from_unixtime、unix_timestamp 这些函数进行转换。int 8 个字节,varchar 15 字节,这在大数据量存储下就非常可观了。
- 使用简单的数据类型。同样保存时间,int 要比 varchar 简单,也比时间戳简单。
- 尽可能使用 not null 定义字段,给出默认值。因为 InnoDB 的存储特性决定对非 not null 的字段,需要一些额外存储,同时会增加 IO 和存储的开销。
- 尽量少用 text 类型,非用不可时最好考虑分表。
反范式优化
我们现在设计的表,一般需要符合第三范式,即非关键字段对做任意候选字段的传递函数依赖,简单来说,就是减少冗余。 反范式优化就是为了查询效率,适当增加冗余,这样查询时多表关联就可以变成单表查询。反范式优化是一种以空间来换取时间的操作。
表的拆分
表拆分分为垂直拆分与水平拆分,垂直拆分解决表的宽度问题,水平拆分解决单表数据量过大的问题。 在优化上,特别是垂直拆分,通过下面三个原则,来提高效率。
- 把不常用的字段单独存放到一个表中。
- 把大字段独立存放到一个表中。
- 把经常一起使用的字段放到一起。
总结
- 优化的第一原则就是针对有问题的 SQL 进行优化,不要为优化而优化,过早优化,谁知道优化的是对的还是错的。
- 尽量保持简单 SQL,一些关联、计算的操作,可以拉到 JVM 进程里来做。
- SQL 语句要关注是否是全表或大数据量扫描,是否使用临时表等,出现这些查询就需要优化了。
- 索引是效率神器,合理使用索引。
- 表的字段,要选择最优的数据类型,避免 null。表结构要进行合理的拆分,常用的放一起,大字段与不常用的应该拆分出去。